
Human Action Recognition/Detection
Introduction
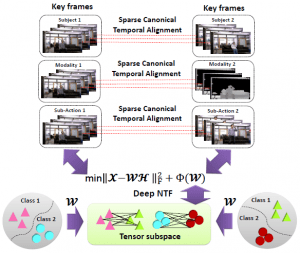
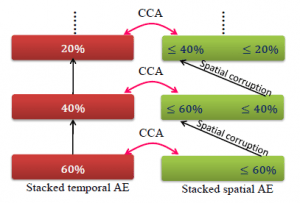
In the action recognition work, we primarily focus on two problems. First, we approach action recognition through temporal alignment, and use sparse modeling to precisely align two videos by selecting key frames in different challenges: sub-action, multi-subject and multi-modality. Second, we try to approach action recognition with noisy data, that is video data contains both spatial and temporal corruptions. In this work, we propose a Coupled Stacked Denoising Tensor Auto-Encoder (CSDTAE) model, which approaches this corruption problem in a divide-and-conquer fashion by jointing both the spatial and temporal schemes together. In particular, each scheme is a Stacked Denoising Tensor Auto-Encoder (SDTAE) designed to handle either spatial or temporal corruption, respectively. SDTAE is composed of several blocks, each of which is a Denoising Tensor Auto-Encoder (DTAE). Therefore, CSDTAE is designed based on several DTAE building blocks to solve the spatiotemporal corruption problem simultaneously.
Related Work
- Chengcheng Jia, Ming Shao, and Yun Fu, Sparse Canonical Temporal Alignment with Deep Tensor Decomposition for Action Recognition, IEEE Transactions on Image Processing (TIP), vol. 26, no. 2, pages 738–750, 2017. [pdf] [bib]
- Chengcheng Jia, Ming Shao, Sheng Li, Handong Zhao, and Yun Fu, Stacked Denoising Tensor Auto-Encoder for Action Recognition with Spatiotemporal Corruptions, IEEE Transactions on Image Processing (TIP), 2017 (in press).